アセットパイプラインは本番環境と開発環境で挙動が違うと言われていますが、具体的にどのように違うのかを深堀りしてみました。
そもそも本番モード、開発モードとは?
アセットパイプラインでは本番モード、開発モードで挙動が違うというのはRails開発者なら誰しもが知っていることかと思います。しかし厳密には本番モード、開発モードという個々のモードが存在するわけではありません。Railsガイドの説明上、明示的に別の表現が用いられているにすぎません。
本番モードとはconfig.assets.compile=falseの状態であることを指します。
config.assets.compileとは動的コンパイルをするかどうか制御するオプションです。
trueの場合は動的コンパイルをする、falseの場合は動的コンパイルをしません。
本番環境の場合はデフォルトでfalseが設定されます。
動的コンパイルとは、リクエストを受けたときに、最新のアセットがコンパイルされていなかった場合に、その場でコンパイルを実行してアセットを生成する仕組みのことです。アセットのコンパイルには多くのメモリを消費するため、本番環境ではconfig.assets.compile=falseにすることが原則とされています。
反対に開発環境では、動的コンパイルを有効にすることで多少メモリを消費したとしても開発作業の効率を優先して、動的コンパイルを有効にするケースが一般的です。 開発環境の場合はデフォルトでtrueが設定されます。
本番モードの仕組み
本番モードの仕組みを簡単に説明します。本番モードでは以下のようなアセットパイプラインの設定になっているのが一般的です。
config.assets.compile=false config.assets.digest=true
config.assets.digest=trueに設定することで、コンパイルされたのファイル名に以下のようなフィンガープリントが付与されます。
/assets/application-47140618c97a4b155143c9a405b56b34e8ed3c3aeb621fb1110dc1f41c99c34c.js
javascriptの場合、アセットパイプラインはjavascript_include_tagでリンクさせます。
<%= javascript_include_tag "application" %>
このように記載することで、出力されたHTMLには以下のようなアセットがリンクされます。

ここで出力された/assets/というディレクトリの実態はデフォルトでは、pubic/aseets配下になります。
本番モードでは、アセットコンパイルは手動で行う必要がありので、以下のコマンドを実行します。
RAILS_ENV=production bin/rails assets:precompile
コマンドを実行すると、pubic/aseetsにapplication.jsのフィンガープリント付きのアセットが生成されることが確認できます。
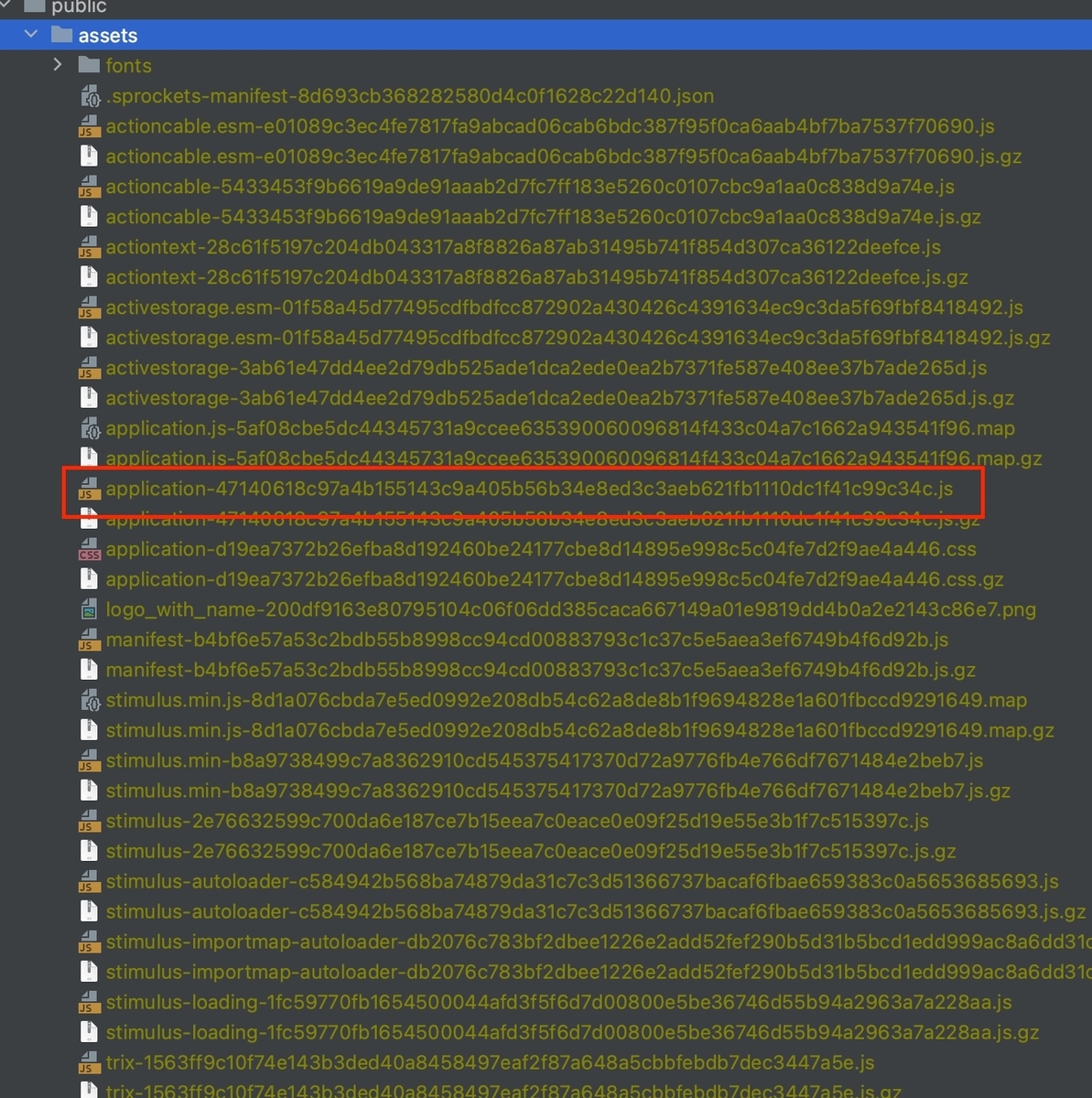
このフィンガープリントはアセットパイプラインがコンパイルする対象のディレクトリにある全てのファイルを連結させたファイルに対してSHA-256でハッシュ化された文字列が付与されます。
アセットの内容が少しでも変更されるとフィンガープリントも変更されます。これによりWebサーバーやCDN等のキャッシュ破棄が正常に動作するようになります。
開発モードの仕組み
次に開発モードの仕組みを説明します。開発モードでは以下の設定になっているのが一般的です。
config.assets.compile=true config.assets.digest=true
本番モードとの違いはconfig.assets.compile(動的コンパイル)がtrueであるかどうかです。
開発モードの場合、assets:precompileのような明示的なコンパイルを実行しません。動的コンパイルが働きますので、あまり意識せずともアセットパイプラインがよしなに動いてくれます。どのようにコンパイルが実行されているかは良い意味でブラックボックス化されています。
詳細は省きますが、簡単に動的コンパイルの流れを説明すると以下のようになります。(Railsのバージョンによって多少の違いがありますのでご容赦ください)
/assets/**へのリクエストをSprocketsが受け取るconfig.assets.compile=trueなので、初回リクエストの場合はアセットをコンパイルしてキャッシュに保存して返却する- 以降のリクエストではアセットに変更がないことを確認する
- 変更がなければキャッシュされた内容を返却する
- 変更がある場合は再度コンパイルした結果をキャッシュに保存して返却する
ここでいうキャッシュとはSprocketsキャッシュストアを指します。デフォルトでは、tmp/cache/assetsのパスが設定されています。
開発モードの場合、アセットが最新であるかどうかの確認やコンパイルが実行されるため、本番モードと比べてメモリ消費が多く、パフォーマンスも低いという特徴があります。
また、Rails6.0の場合下記に該当するassetsはプロジェクトディレクトリのどこにも存在しません。

このことから、動的コンパイルモードの場合はアセットそのモノを作成せずに、キャッシュを使って動的にアセットを生成していることが伺えます。コンパイル対象となるアセットに変更がある場合は、キャッシュの中身を更新した後に、動的にアセットを生成しているようです。
参考
config.assets.compile=true in Rails production, why not? - Stack Overflow